2022-05-16
Data scientists concentrate on making sense of data through exploratory analysis, statistics, and models. Software developers apply a separate set of knowledge with different tools. Although their focus may seem unrelated, data science teams can benefit from adopting software development best practices. Version control, automated testing, and other dev skills help create reproducible, production-ready code and tools.
Rachael Dempsey recently asked the Twitter community for suggestions on resources that data scientists can use to improve their software development skill set.
We received so many great recommendations that we wanted to summarize and share them here. This blog post walks through software development best practices that your team may want to adopt and where to find out more.
The areas discussed below are:
It’d be great if we could open an R script, click Run, and we have the output we need. However, code doesn’t always “just work.” As our projects get bigger and more complex, we need structure so that they are easy to manage and understand.
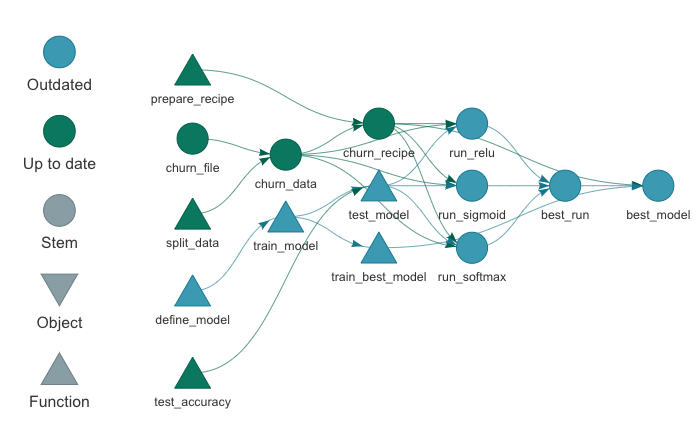
As Daniel Chen says in his Structuring Your Data Science Projects talk, a proper project structure gets us to the happy place where our code runs. Existing principles, templates, and tools can guide you:
Organized projects allow data scientists to remain productive as their projects grow.
A data scientist can test a function by inputting some values, seeing if the output is what you expect, modifying the code if there are issues, and rerunning to check the values again. However, this process leaves a lot of room for error. It’s easy to forget what changed and cause something else to break.
Automated testing offers a better option, such as with the pytest package or testthat package. Automated testing focuses on small, well-defined pieces of code. Data scientists write out explicit expectations. Tests are saved in a single location, making them easy to rerun. When a test fails, it’s clear where to look for the problem.
from foobar import foo, bar
def test_foo_values():
assert foo(4) == 8
assert foo(2.2) == 1.9
def test_bar_limits():
assert bar(4, [1, 90], option=True) < 8
# If you want to test that bar() raises an exception when called with certain
# arguments, e.g. if bar() should raise an error when its argument is negative:
def test_bar_errors():
with pytest.raises(ValueError):
bar(-4, [2, 10]) # test passes if bar raises a ValueErrorIncorporating automated testing in a workflow exposes problems early and makes it easier to alter code.
Have you ever had a script that worked great, but now you can’t reproduce the results on a new laptop? This may happen because of changes in the operating system, package versions, or other factors. You have to spend time figuring out why the output is suddenly different.
A reproducible environment ensures workflows run as they did in the past. Your team controls everything needed to run a project in a reproducible environment. Each person running the code can expect the same behavior since everything is standardized.
Virtual environments for Python or the renv package for R are examples of the tools that can help a data science team reproduce their work. They record the version of loaded packages in a project and can re-install the declared versions of those packages.
For example, say one of your projects uses dplyr::group_map(), introduced in dplyr v0.8.0. If a team member runs the code with an older version of dplyr, they will run into an error. The renv package captures the state of the environment in which the code was written and shares that environment with others so that they can run the code without issue. (Try out Josiah Parry’s example on GitHub.)
With reproducible environments, data scientists can collaborate on work and validate results regardless of when and where they are running code.
Data scientists produce many files. As these files evolve throughout a project, keeping track of the latest version becomes more challenging. If the team collaborates on the same file, someone may use an outdated version and has to spend time reconciling mismatched lines of code.
Version control with tools like Git and GitHub can alleviate these pains. Teams can manage asynchronous work and avoid conflict or confusion. It’s easy to track the evolution of files, find (and revert) changes, and resolve differences between versions.
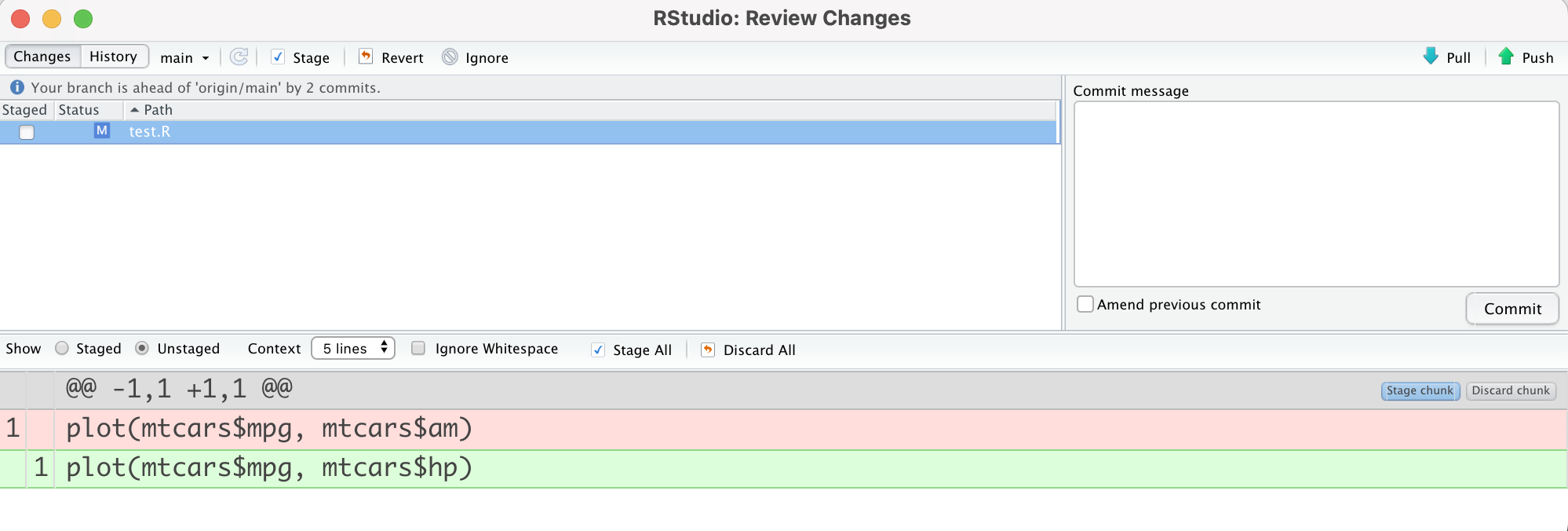
mtcarshp < /code > insteadof < code > mtcarsam)
Using version control in data science projects makes collaboration and maintenance more manageable.
These are just a few areas that data science teams should concentrate on to improve their software development skill set. We hope that you find them helpful and are excited to learn more!
Interested in developing holistic workflows, improving debugging processes, and writing non-repetitive code? Register for What They Forgot to Teach You About R at rstudio::conf(2022), a two-day session led by Shannon McClintock Pileggi, Jenny Bryan, and David Aja. Learn more on the rstudio::conf workshop page.