2025-12-05 AI Newsletter

External news
Model releases
The last edition of this newsletter was released in the midst of a flurry of frontier model releases that continued through Thanksgiving. These releases included Gemini 3 Pro, Gemini 3 Pro Image (aka Nano Banana Pro), GPT 5.1 Pro, GPT 5.1-Codex-Max, Deepseek V3.2, Grok 4.1. We’ve now had a week to experiment with these releases, and there are two standouts.
First, Claude Opus 4.5 is now the best coding model available. Up to this point, Anthropic kept its three model lines—Haiku (small, cheap), Sonnet (balanced daily driver), and Opus (very capable, slow, expensive)—at very different price points. With the 4.5 round of releases, however, Anthropic increased the price of Haiku and decreased the price of Opus, converging them towards the Sonnet pricing:

Second, Google Gemini’s Nano Banana Pro is a highly capable image model. Notably for data scientists, Nano Banana Pro is the first image model that can sometimes generate coherent technical diagrams. For example, in response to “Infographic explaining how the ellmer R package works,” the model created this diagram:
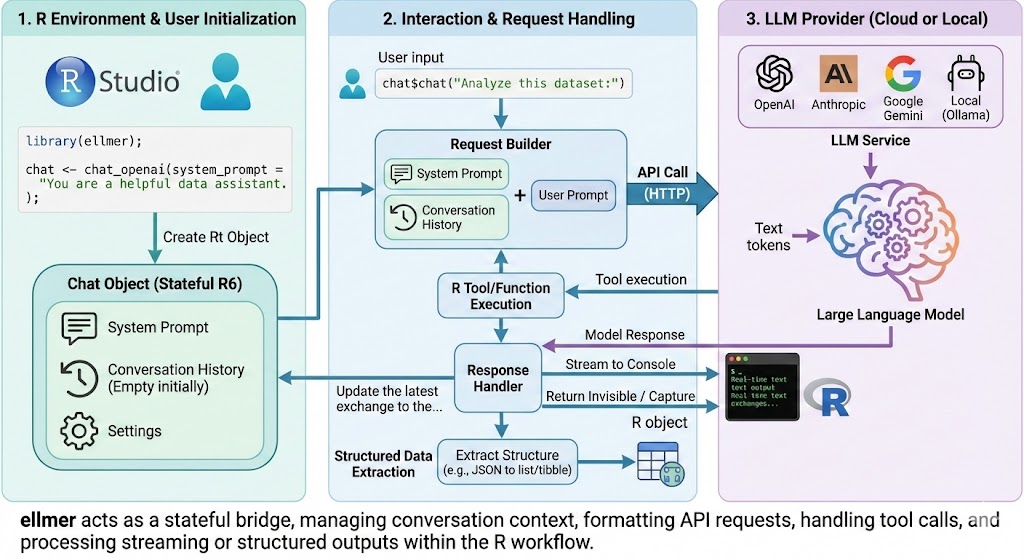
This probably isn’t how we would have structured the diagram, and some of the arrows and icon placements are questionable. However, diagrams like this represent a step change from previous generations of image models, which frequently misspell text and produce nonsensical relations between elements.
Posit news
- vitals 0.2.0, an R package for evaluating LLM tools built with ellmer, is now on CRAN. The release includes image support, precise latency measurement, better error messages, and more comprehensive logging.
- Over the past six months, we’ve been tracking how well LLMs generate R code using the `are` eval from the vitals package. You can see those blog posts here and here. To better keep this analysis up-to-date, we created a Shiny app that compares model performance. We’ll update this app as new models come out.
- Wes McKinney wrote an in-depth post exploring LLMs’ difficulty with simple arithmetic. If you want to learn more, this post from 2024 is also an interesting dive into some of the fundamentals of why LLMs are surprisingly poor at arithmetic.
Terms
If you’ve used LLMs in different settings, you might have noticed that the cost depends on how you’re using the LLM. For example, if you go to https://claude.com/pricing, you’ll see that you can pay $0, $17, or $100 a month for different Claude subscriptions. But then if you go to https://claude.com/pricing#api, you’ll see prices for the API in terms of millions of tokens.
This is the difference between consumer and API pricing. Consumer pricing is typically a flat subscription fee that lets you use a set of applications from the provider, with usage limits but no per-token costs. API pricing is for programmatic use where you pay according to your token usage, which is why model price differences matter when choosing between models.
When we discuss model prices in this newsletter, we’re typically referring to API pricing, since tools like ellmer and chatlas use LLM APIs. Your costs will be determined by each model’s API pricing.
Consumer chat subscriptions also typically don’t include API access. You’re only paying for access to the chat app, and API usage is paid for separately.
Learn more
- This Anthropic post discusses new research on long-running agents that work across multiple context windows. Their key insight is to have one agent (the “initializer”) make a detailed checklist without actually executing any of the steps, and then have later agents read the plan, make incremental progress, and provide updates.
- AI-generated images can be watermarked so that they can be later reliably detected as AI-generated. Google now allows you to ask whether an image is AI-generated in its app.
- A new NYT article reports on internal conversations at OpenAI about sycophancy and AI-induced psychosis.




