2025-08-29 AI Newsletter



Over the last few months, Posit’s Sara Altman and Simon Couch have been piloting an internal AI newsletter. Opinionated and curated, it’s intended to give readers just enough information to stay on top of the most important developments that are happening both inside the company and in the wider world. Starting today, the newsletter will be shared every other week on the Posit Blog.
External news
There has been much discussion on the environmental impact of LLMs, but it’s typically been difficult to quantify because the major AI labs had not released reports. In the last few months, there have been some updates.
First, earlier in August, Mistral AI released a comprehensive environmental impact report on the training and deployment of their largest model to date. At the time, none of the three major AI labs (OpenAI, Anthropic, Google) had released a similar report.
Last week, however, Google released a report measuring the environmental impact of their Gemini series models. The report estimates that a typical Gemini query uses 0.24Wh of electricity, about the same as watching TV for 9 seconds, and 5 drops of water.
Our World in Data’s Hannah Ritchie wrote a great blog post that summarizes the report and contextualizes the energy usage numbers, arguing “unless you’re an extreme power user, asking AI questions every day is still a rounding error on your total electricity footprint.”
[caption id="attachment_30264" align="alignleft" width="800"]
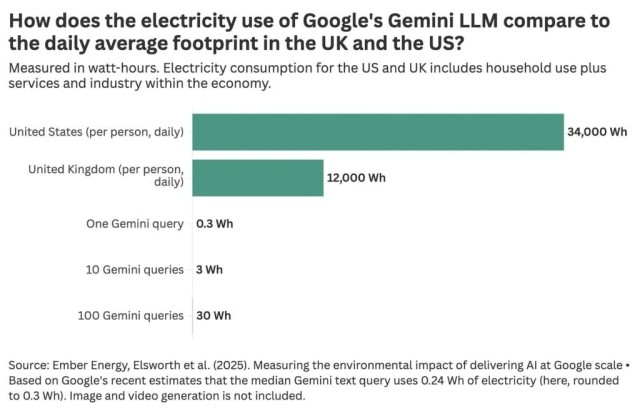
Notably, the report does not clarify what a “typical” query is or provide distributional estimates. For example, how does the impact of a 30-minute coding session with Gemini CLI compare to that of a typical Gemini query? These metrics also only tell you the individual impact of a Gemini query, not the aggregate impact.
Posit news
Two weeks ago, Posit officially announced Positron Assistant and Databot, the two AI assistants available in Positron. Positron Assistant is a coding assistant with access to your R or Python session, and Databot is designed to dramatically accelerate exploratory data analysis.
The product announcement is also a good introduction to Posit’s perspective on responsible AI tools.
You can read more about Databot in these two blog posts: Introducing Databot and Databot is not a flotation device.
Terms
The energy demands of AI usage are largely concentrated in two stages:
- At training time, huge corpora of content from the Internet (largely taken without consent from its authors) are processed in a training algorithm. The output of this process is, roughly, an LLM.
- Then, at inference time, some text is passed to the LLM, and a response is generated. This process is also computationally intensive.
Reasoning models, one of the current frontiers of LLM development, generate large amounts of text even before producing a final response. This results in even greater energy demands at inference time (often called test-time compute). The previously mentioned Mistral AI environmental impact report measured the impact of training, inference, and many other factors, and found that training accounted for 85% of emissions altogether, while Google’s environmental report only investigated inference.
Learn more
- Casey Newton wrote a reflection on the surprising aftermath of “shutting down” access to previous-generation LLMs alongside new releases.
- Two interesting articles on coding agents: this one describes the high-level idea behind major coding agents like Claude Code, Gemini CLI, and Codex, while this one dives deeper into Claude Code.
- Simon Willison recaps The Summer of AI Bugs, showing that serious security vulnerabilities are widespread among many popular AI tools.
- This Posit Blog post by Isabella Velásquez walks through the process of using local LLMs, and talks about how she used a spare computer as her own personal AI server.
- Simon wrote this post after realizing that, at some point in the last year, frontier LLMs gained the ability to write workable tidymodels code without additional prompting.

Sara Altman

Simon Couch
Related Content

The Test Set 1 Year

Posit wins two Snowflake Partner Awards and launches Posit Assistant a...
