Running AI/LLM Hackathons at Posit: What We’ve Learned


At Posit, we’ve been running internal AI/LLM hackathons to explore ideas, build prototypes, and understand how these technologies fit into our work. So far, we’ve facilitated 18 groups, with more scheduled, pulling in participants from across the organization.
The team at Posit includes many skeptics. Some saw the scale of the hype and assumed it must be overblown—just another fad-driven tech cycle. Others, with backgrounds in machine learning or early exposure to LLMs, viewed the technology as fundamentally limited, shaped by critiques like the “stochastic parrot” argument. And many, working in a culture that values accuracy and reproducibility, were cautious of tools that can sound convincing without being reliable—something often overlooked in broader AI conversations.
Rather than push a top-down agenda or set out to convince the skeptical, we chose an approach that encouraged exploration. By making participation opt-in and hands-on, we aimed not to convert skeptics, but to give everyone the chance to build their own informed perspective.
We also wanted to prioritize programmatic interaction with LLMs. While chat interfaces and code autocompletion can be very useful, these methods do not provide a deep understanding of the technology’s true capabilities or its limitations. Hands-on development fosters a more practical and realistic view of what LLMs can and cannot do.
Our approach
- Eight-person groups. This size balances diverse perspectives while keeping the share-out sessions manageable.
- Structured kickoff. Each session begins with 2.5 hours of instruction from our CTO, Joe Cheng. The content is focused on how to programmatically use LLMs, not on how they work. We cover prompt engineering, tool calling, RAGs, and overviews of the different cutting-edge models.
- Individual projects. Each participant works on their own project. It can be related to their work at Posit, but we also encourage exploring personal interests as well.
- Flexible work time. Participants commit to at least 4 hours working on their project over the three days between the kickoff and shareout at the end of the hackathon.
- Dedicated support. A Slack channel provides real-time answers, brainstorming support, pairing opportunities, as well as active troubleshooting.
- Resource access. We provide API keys for OpenAI and Anthropic and guide teams on how they can use models available through AWS Bedrock on Workbench.
- Show, don’t tell. Each participant presents their results and key learnings in a 1.5-hour sharing session at the end.
- Open participation. We invited participants from across the company to sign up regardless of their role, department, seniority, or coding ability.
- Executive buy-in. Having the CTO actively lead sessions signaled that participation was both encouraged and valued by leadership.
What we’ve learned
- One of our original theories holds: programmatic interaction leads to deeper understanding. Interacting with LLMs programmatically—rather than through a chat interface or as code completion—provides deeper insight into both the challenges and the possibilities.
- Hallucinations are very real and often hard to detect. Participants often believe a web search, data source, or API they provided is being used, but instead, the LLMs are just shockingly good at making plausible-sounding responses. As an example, in an early cohort, one participant attempted to create a chatbot that analyzed GitHub repos and reported not only what languages were used, but also what popular frameworks were used. Their implementation simply directed the LLM to "tell me what frameworks are used in https://github.com/abc/xyz" without giving it any more information, a way to fetch web pages, or a tool that could call out to the GitHub API. The LLM answered gamely, never noting that it didn't actually know anything about those repos (particularly more recent ones) – it appeared to guess (quite plausibly) entirely based on the name of the repo.
- Huge range of results. Some projects produce applications that are useful and inspiring from day one, while others result in "failures" that never quite work as intended—or some that even provided misleading results. Going in predicting which projects will bear fruit and which will not is surprisingly difficult.
- Failures teach as much as successes. Groups often learn the most from what doesn’t work, whether due to model limitations, data challenges, or incorrect assumptions. Everyone is engaging in an experiment, and that is critical framing for the entire exercise.
- Providing tooling without dictating choices can give participants a strong starting point. We've seen great success offering Posit Team access to LLM models on Bedrock, along with Shiny and Ellmer or Chatlas. This gave those looking for structure a quick, secure way to start. At the same time, we left room for flexibility—some of the most creative and successful projects took entirely different paths, using languages like Go or integrating with business automation tools like Workato.
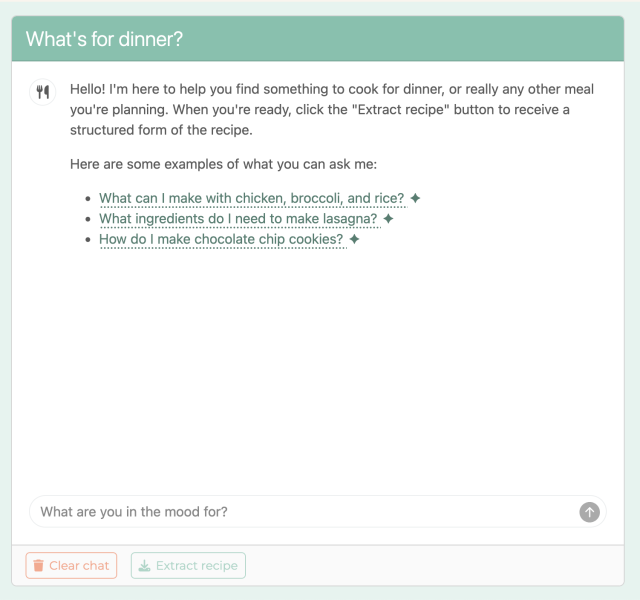
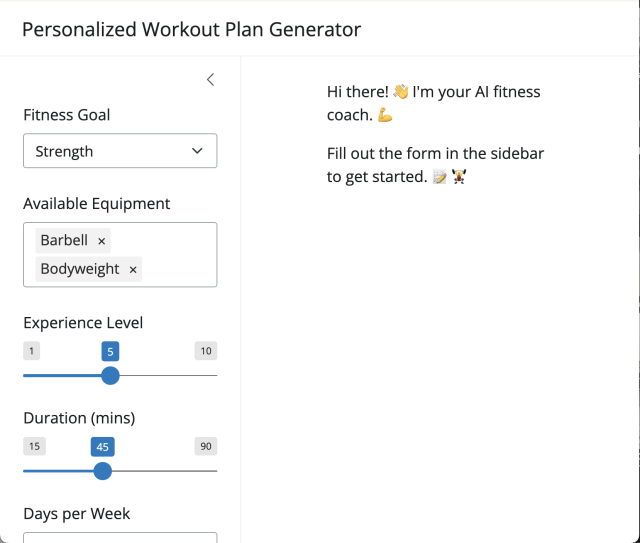
Did the sessions work? Time will tell, but early signs are very encouraging. Many participants completed successful projects, which you can check out a sampling of in this gallery. What’s for Dinner, AI Workout Plan, Dataset Generator, and the R Plot Alternative Text Generator were all the direct result of hackathon projects.
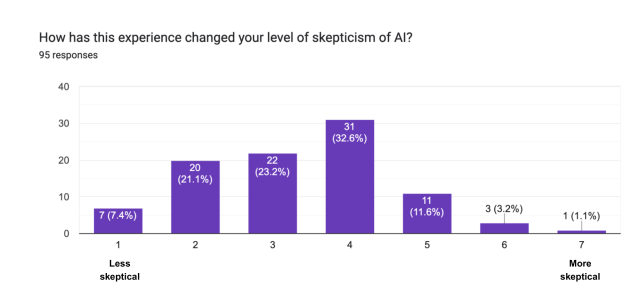
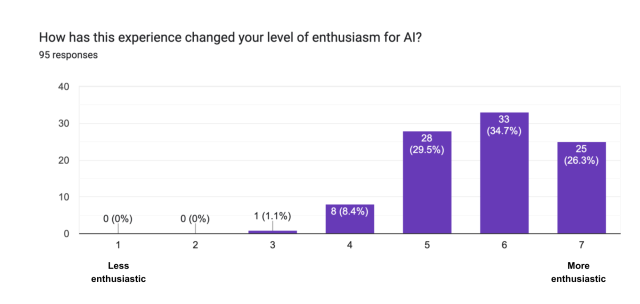
Another positive data point was our post-hackathon survey feedback, which was all exceptionally positive. Those surveys also showed that the average skepticism score decreased appreciably, with a bigger increase in enthusiasm for the potential of LLMs. It is worth reiterating that moving those scores was not an explicit goal. Perhaps the single most important outcome was several unsolicited comments from across the organization on the level of discourse about AIs and LLMs across a variety of teams. They all noted that everyone is operating at a noticeably higher level of understanding than just a few months before.
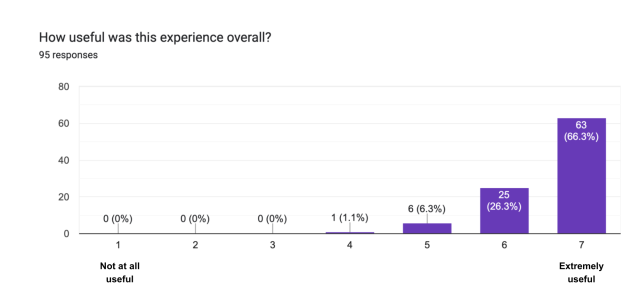
As we continue running hackathons and developing LLM-driven solutions, we’ve identified key areas to focus on: robust validation, effective retrieval-based augmentation, seamless tool-calling API integrations, and refining prompt engineering best practices. The way a prompt is structured has a significant impact on results, especially when generating reliable, structured output. Techniques like few-shot prompting, output schema enforcement, and self-consistency checks help improve accuracy and reduce inconsistencies.
Providing accessible tooling also makes a difference. Packages like Shiny, Ellmer, Chatlas, and Ragnar help lower the barrier for building interactive applications and experimenting with different LLM providers. Making it easier to prototype and test real-world use cases helps teams move beyond theoretical discussions and towards practical insights.
New challenges will emerge, but one thing is clear—organizational competence with LLMs comes from direct, hands-on engagement. By experimenting, refining our approaches, and sharing insights, we can determine where LLMs provide real value while working actively to mitigate or avoid their limitations.
What’s next
We’ll continue refining our hackathon format and exploring LLM-driven ideas. We consider it an imperative that a range of folks across the organization engage first with the tools through experiments and then later determine if and how it should inform their work.
Some key questions we’re asking:
- How do we move the best prototypes into production?
- What internal AI-powered tools can most improve our own workflows?
- Where can AI/LLMs safely and responsibly add the most value across Posit’s products?
- What further features are needed for our core products to enable the builders we serve to leverage these tools responsibly and effectively?
As we run more sessions, we’ll share further insights. If you’re experimenting with AI in your own work, we’d love to hear about it.
We will also be running a version of this hackathon during the “Programming with LLM APIs: A Beginner’s Guide in R and Python” workshop at posit::conf in Atlanta on Sept 16th, so if you are interested, we would love to see you there. Be sure to sign up for that specific workshop when registering! We are looking forward to seeing what all our amazing users create with this new class of powerful tools!

Andrew Holz
Related Content

What makes Posit different from proprietary analytics vendors

The Test Set 1 Year
