Which AI model writes the best R code?



Compare model performance in Shiny app
In a series of past blog posts, we evaluated how well various models generate R code. To do so, we used the vitals package, a framework for LLM evaluation. vitals contains functions for measuring the effectiveness of an LLM, as well as are, a dataset of challenging R coding problems and their solutions. We evaluated model performance on this set of coding problems.
Since we started this series, there has been a proliferation of new models. To help keep this evaluation up-to-date, we created a Shiny app to visualize results. Going forward, we’ll add new results to this app. The app lets you select and compare any of the models we’ve evaluated on both performance and cost. You can see the app here.
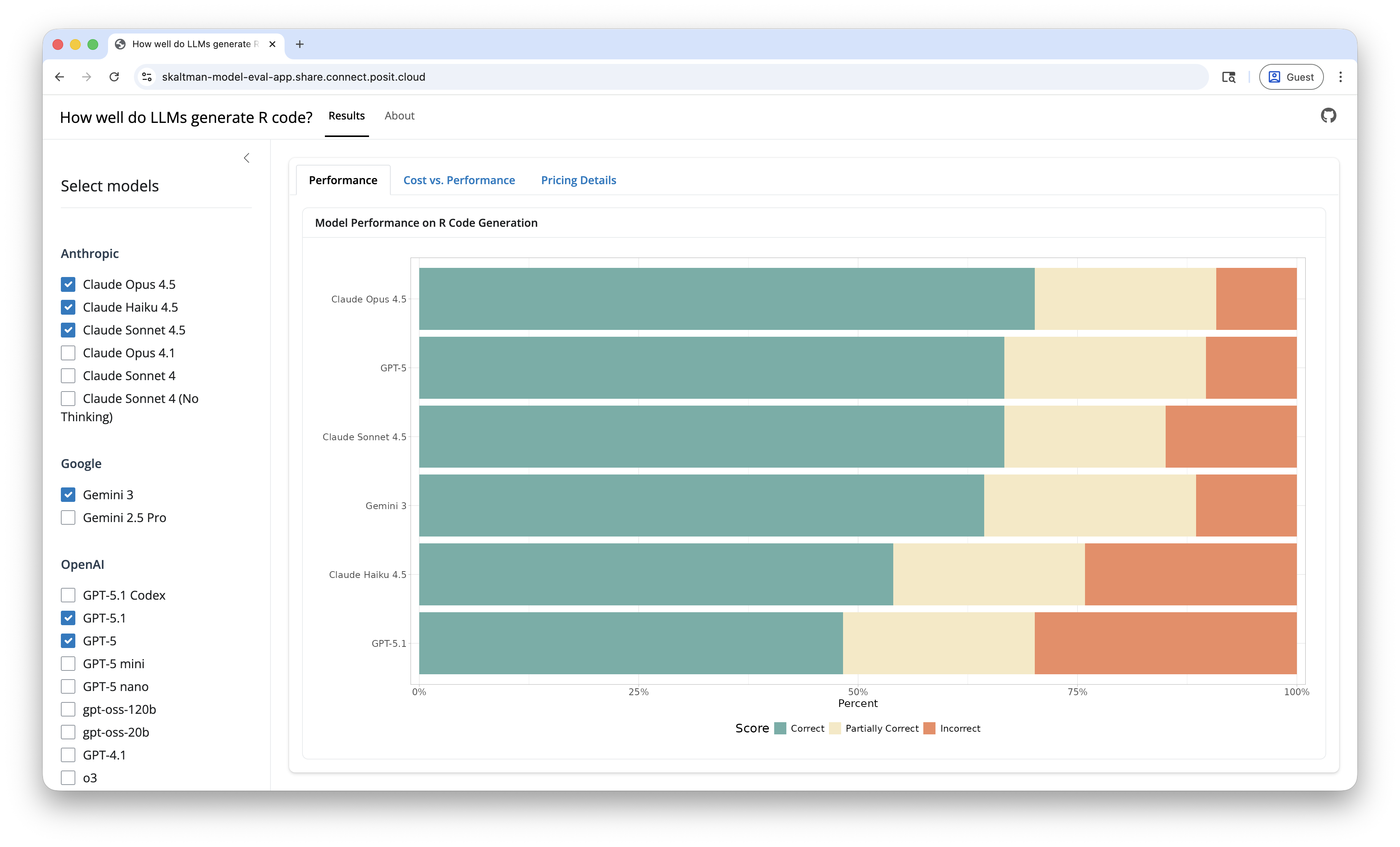
We’ll summarize current results in this post, but check out the app to create your own custom comparisons.
Current recommendation: Claude Sonnet 4.5, Claude Opus 4.5, or OpenAI GPT-5
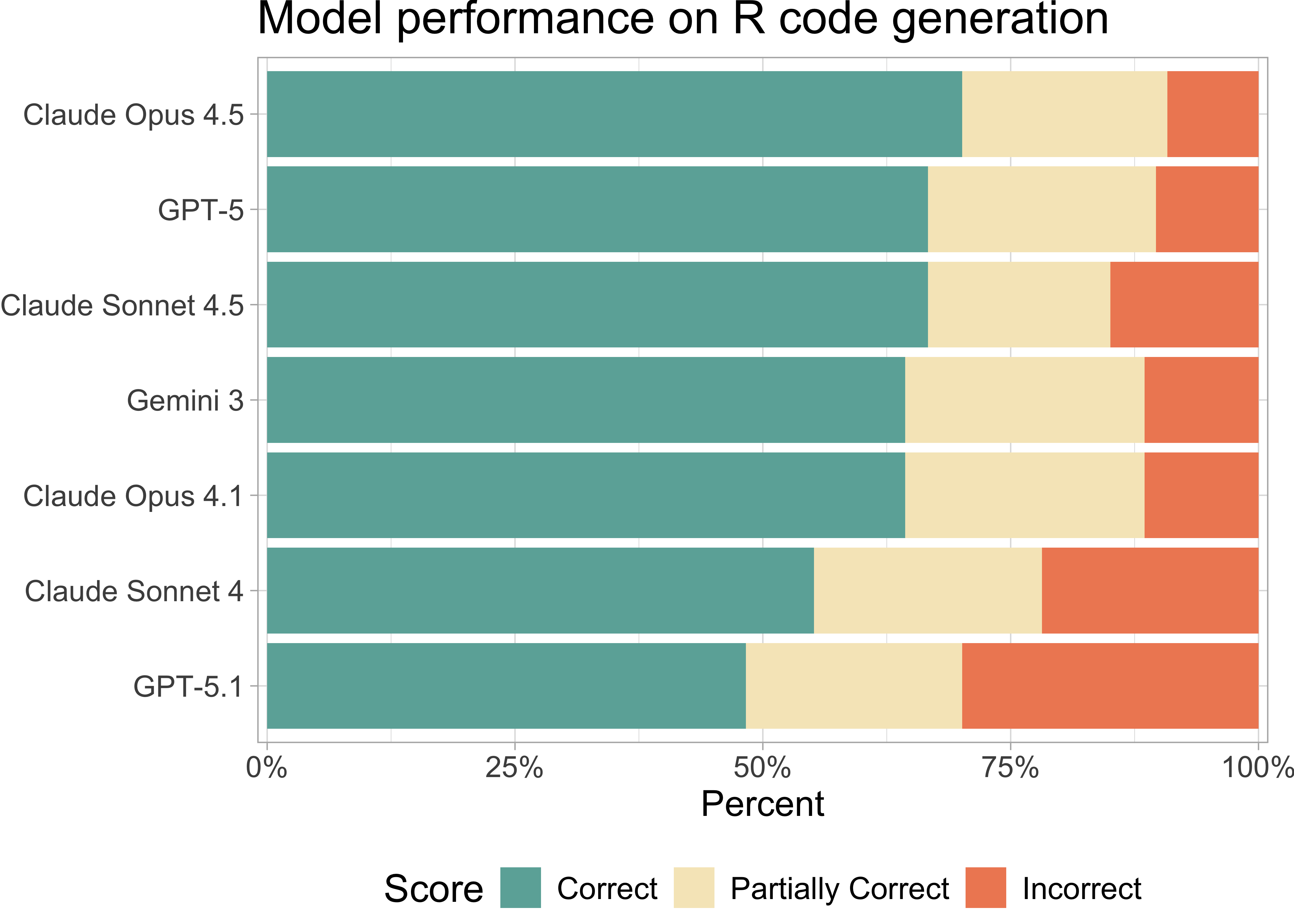
For R coding tasks, we recommend using Claude Sonnet 4.5, Claude Opus 4.5, or OpenAI GPT-5. Gemini 3 Pro, Google Gemini’s latest model, also scored well. Notably, Claude Sonnet 4.5, released in September, shows marked improvements over version 4.
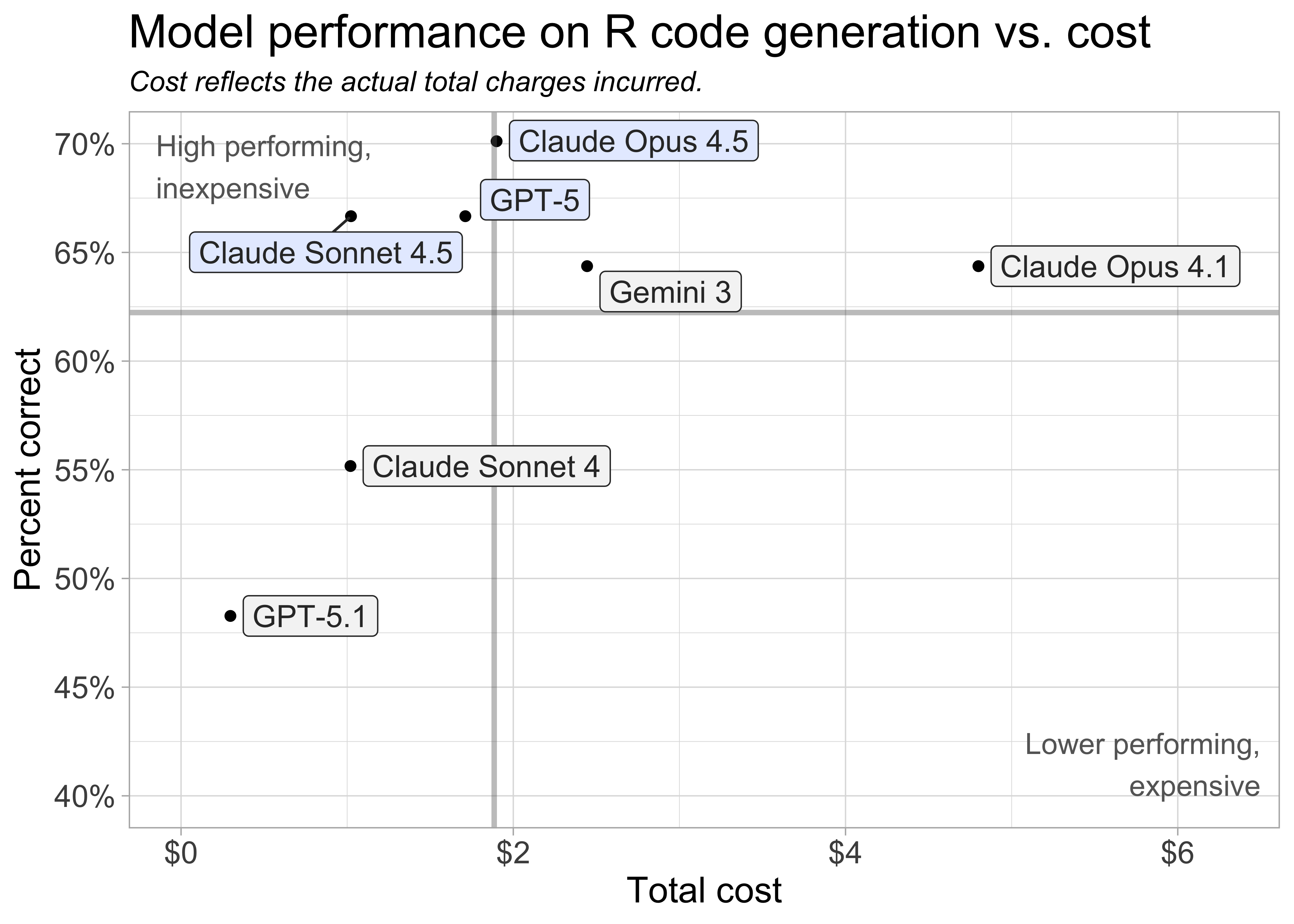
Take token usage into account
A token is the fundamental unit of data that an LLM can process (for text processing, a token is approximately a word). Different models use vastly different amounts of tokens. As a result, a model that is inexpensive on a per-token basis can, in practice, cost much more if it produces longer outputs.
The above plot shows the actual costs incurred during the evaluation so it takes token count and per token cost into account.
Key insights
Claude Opus 4.5, Claude Sonnet 4.5, and OpenAI GPT-5 are the current best performers on the set of R coding tasks.
These models represent some of the latest model releases from the major AI labs.
Claude Opus 4.5 (released November 2025) and Claude Sonnet 4.5 (released September 2025) show significant improvements over their predecessors. However, OpenAI’s most recent release GPT-5.1 (November 2025) performed worse than GPT-5.1
Gemini 3, Google Gemini’s latest model, also performed well. It is slightly more expensive than our top three recommendations.
Claude models show consistent improvement across versions. Claude Sonnet 4.5 notably outperforms version 4 (released May 2025), and Opus 4.5 is cheaper and performed better than Opus 4.1.
Pricing
LLM pricing is typically provided per million tokens. In our evaluation process, each model used between 26,070 and 31,400 input tokens and between 26,450 and 198,800 output tokens.
| Model Pricing and Performance Details | ||||||
| Sorted by percent correct (descending) | ||||||
| Model | Input (per 1M tokens) | Output (per 1M tokens) | Input Tokens Used | Output Tokens Used | Total Cost | % Correct |
|---|---|---|---|---|---|---|
| Claude Opus 4.5 | $5.00 | $25.00 | 31,401 | 69,699 | $1.90 | 70.1% |
| Claude Sonnet 4.5 | $3.00 | $15.00 | 31,314 | 61,936 | $1.02 | 66.7% |
| GPT-5 | $1.25 | $10.00 | 26,067 | 167,873 | $1.71 | 66.7% |
| Claude Opus 4.1 | $15.00 | $75.00 | 31,314 | 57,695 | $4.80 | 64.4% |
| Gemini 3 | $2.00 | $12.00 | 29,610 | 198,754 | $2.44 | 64.4% |
| Claude Sonnet 4 | $3.00 | $15.00 | 31,314 | 61,704 | $1.02 | 55.2% |
| GPT-5.1 | $1.25 | $10.00 | 26,067 | 26,453 | $0.30 | 48.3% |
Methodology
- We used ellmer to create connections to the various models and vitals to evaluate model performance on R code generation tasks.
- We tested each model on a shared benchmark: the
aredataset (“An R Eval”).arecontains a collection of difficult R coding problems and a column,target, with information about the target solution.
- Using vitals, we had each model solve each problem in
are. Then, we scored their solutions using a scoring model (Claude 3.7 Sonnet). Each solution received either an Incorrect, Partially Correct, or Correct score.
You can see all the code used to evaluate the models here. If you’d like to see a more in-depth analysis, check out Simon Couch’s series of blog posts, which this post is based on, including Claude 4 and R Coding.
Footnotes
GPT-5.1 Codex, which is not shown here but can be seen in the app, performed substantially better than GPT-5.1.↩︎

Sara Altman

Simon Couch
Related Content

Snowflake Native Apps vs. Connected Apps for financial services

We prove model governance by live evidence, not paperwork
