Which AI model writes the best R code?



LLMs can now help you write R code. There are many available models, so which one should you pick?
We looked at a handful of models and evaluated how well they each generate R code. To do so, we used the vitals package, a framework for LLM evaluation. vitals contains functions for measuring the effectiveness of an LLM, as well as a dataset of challenging R coding problems and their solutions. We evaluated model performance on this set of coding problems.
Current recommendation: OpenAI o4-mini or Claude Sonnet 4
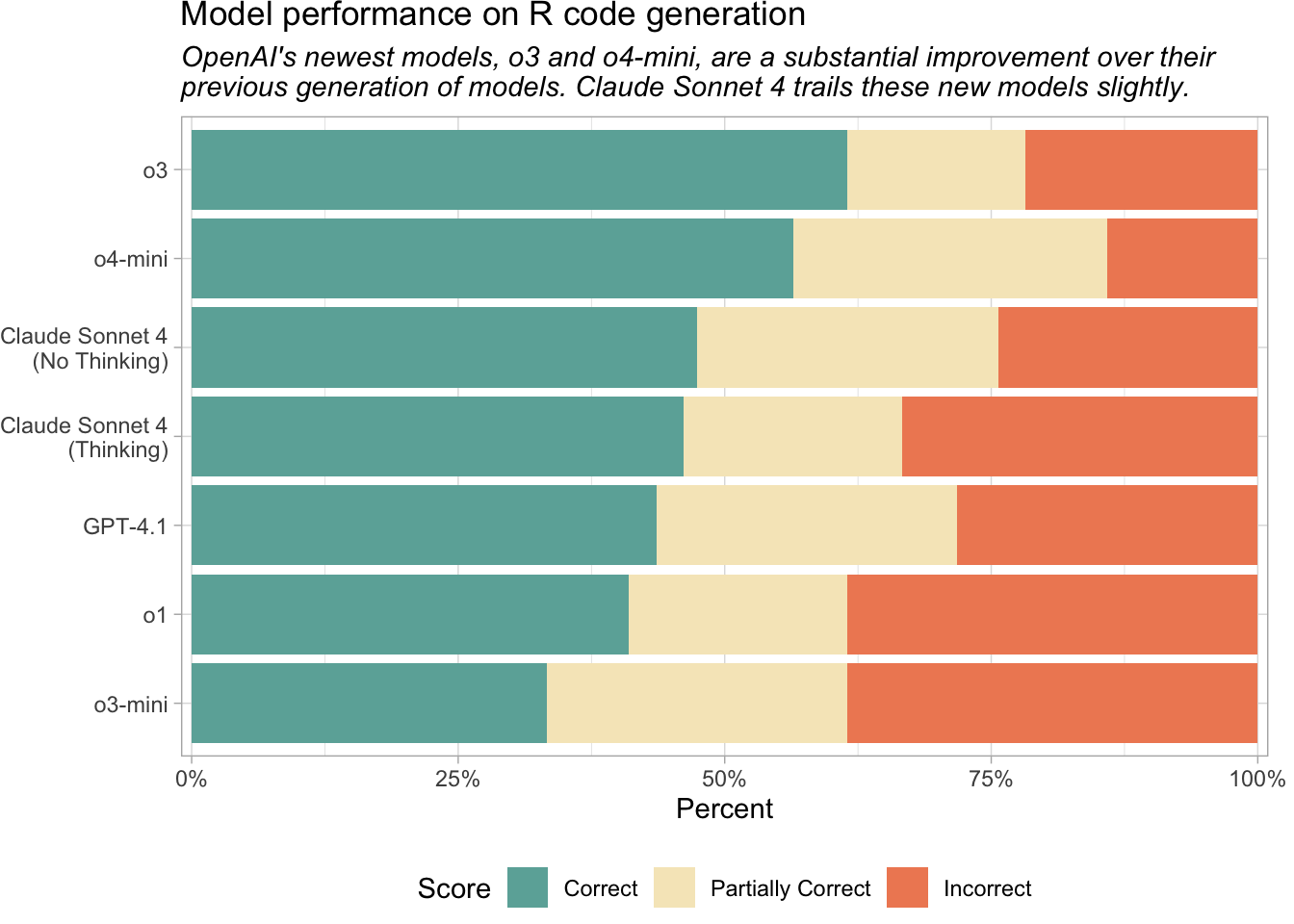
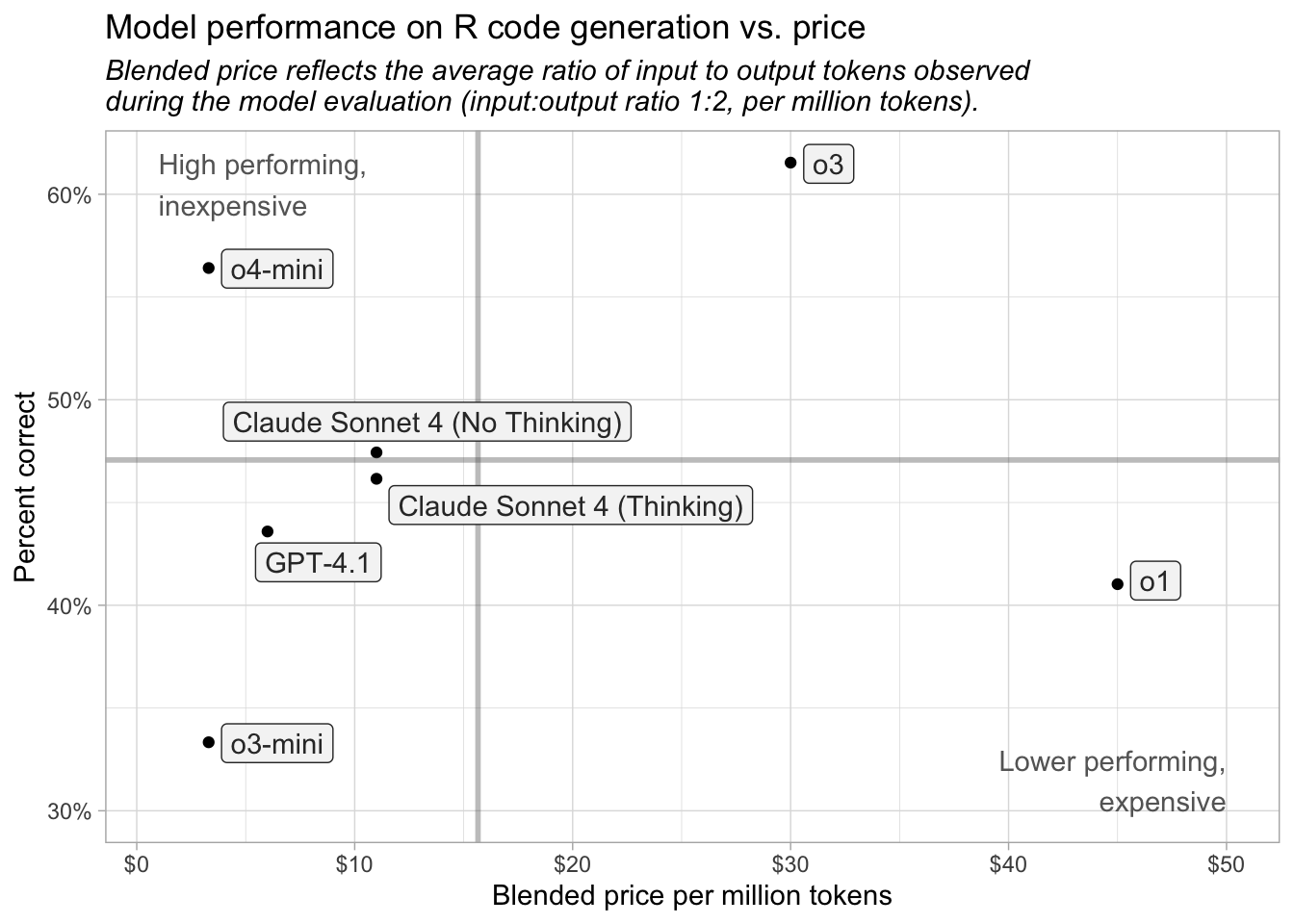
For R coding tasks, we recommend using OpenAI’s o4-mini or Anthropic’s Claude Sonnet 4. OpenAI’s o3 performed the best on this evaluation but is also ten times more expensive than o4-mini and around three times more expensive than Sonnet 4.
Reasoning vs. non-reasoning models
Thinking or reasoning models are LLMs that attempt to solve tasks through structured, step-by-step processing rather than just pattern-matching.
Most of the models we looked at here are reasoning models, or are capable of reasoning. The only models not designed for reasoning are GPT-4.1 and Claude Sonnet 4 with thinking disabled.
Many R programmers seem to prefer Claude Sonnet and it remains a good solution for R code generation, even though o3 and o4-mini performed slightly better in this evaluation.
Take token usage into account
A token is the fundamental unit of data that an LLM can process (for text processing, a token is approximately a word). Reasoning models, including o4-mini, often generate significantly more output tokens than non-reasoning models. So while o4-mini is inexpensive per token, its actual cost can be higher than expected.
In our evaluation, however, o4-mini was still tied for the least expensive model overall, despite using more output tokens than any model except o3 (another reasoning model).
If you have ideas for how we could better visualize or communicate model cost, we would like to hear your suggestions.
Key insights
OpenAI’s o3 and o4-mini and Anthropic’s Claude Sonnet 4 are the current best performers on the set of R coding tasks.
OpenAI’s o3 and o4-mini (April 2025) and Anthropic’s Claude Sonnet 4 (May 2025) are the newest models we evaluated. Anthropic also released Claude Opus 4, which we did not evaluate, alongside Sonnet 4.
Claude Sonnet 4 performed similarly regardless of whether thinking was enabled.
o3 and o4-mini performed much better than the previous generation of reasoning models, o1 and o3-mini, which were released in December 2024 and January 2025, respectively.
Pricing
LLM pricing is typically provided per million tokens. Note that in our analysis, o3 and o4-mini performed similarly for R code generation, but o3 is about ten times more expensive. OpenAI uses the “mini” suffix for models that are smaller, faster, and cheaper than the other models.
| Price per 1 million tokens | ||
| Name | Input | Output |
|---|---|---|
| o3 | $10.00 | $40.00 |
| o4-mini | $1.10 | $4.40 |
| Claude Sonnet 4 | $3.00 | $15.00 |
| GPT-4.1 | $2.00 | $8.00 |
| o1 | $15.00 | $60.00 |
| o3-mini | $1.10 | $4.40 |
In our evaluation process, each model used between 29,600 and 125,300 input tokens and between 46,570 and 146,800 output tokens. The entire analysis cost around $10.
Methodology
- We used ellmer to create connections to the various models and vitals to evaluate model performance on R code generation tasks.
- We tested each model on a shared benchmark: the
aredataset (“An R Eval”).arecontains a collection of difficult R coding problems and a column,target, with information about the target solution.
- Using vitals, we had each model solve each problem in
are. Then, we scored their solutions using a scoring model (Claude 3.7 Sonnet). Each solution received either an Incorrect, Partially Correct, or Correct score.
You can see all the code used to evaluate the models here. If you’d like to see a more in-depth analysis, check out Simon Couch’s series of blog posts, which this post is based on, including Evaluating o3 and o4-mini on R coding performance.

Sara Altman

Simon Couch
Related Content

Don't bring a spreadsheet to a data fight

Snowflake Native Apps vs. Connected Apps for financial services
