Gemma 4: A new, budget-focused model in Posit AI


Gemma 4 is now available in Posit Assistant via the Posit AI provider. It's priced at a tenth of the price of Claude Sonnet 4.6 and less than a third of the price of our current cheapest offering, Claude Haiku 4.5. While less capable than Haiku, it's a good fit for basic data analysis and quick agentic coding tasks in R and Python. Here it is in action:
To use it, open Posit Assistant in RStudio or Positron and update to the most recent version of Posit Assistant when prompted. Then, select Gemma 4 in the model selector.
Meet Gemma 4
Gemma 4 26B A4B is a recent open-weights model release from Google Gemini. Up until this point, models of this size—small enough to run comfortably on high-end consumer laptops—were on our radar but not yet capable enough to drive an agent harness like Posit Assistant. This has changed in the last few months with releases like Gemma 4; this model is one of a couple "small" LLM releases that have really caught our attention recently.
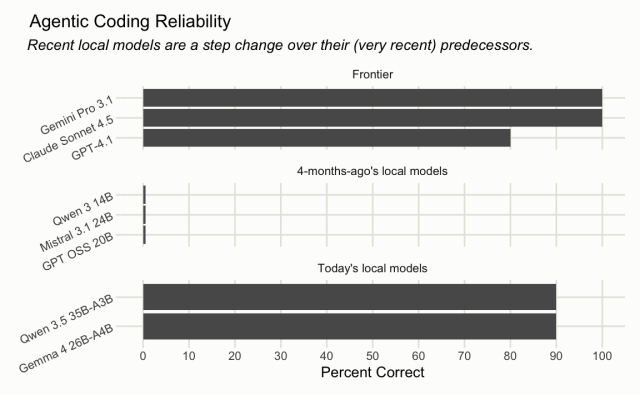
While capable and very cost-efficient, Gemma 4 is more "jagged" than the Claude models we currently serve as part of Posit AI. The model will sometimes complete a substantive agentic coding session with remarkable coherence, stringing together reasonable tool calls and never losing the larger thread of the conversation. Just as often, the model will misinterpret your intent or lose the thread of the conversation after a few turns. Like frontier models of a year ago, you will want to steer Gemma 4 actively and audit code and output closely.
We recommend Gemma 4 for basic data analysis tasks. We do not recommend Gemma 4 for long-running agentic coding tasks.
Choosing a model
You can switch between available models at any time in Posit Assistant, including mid-conversation. So how should you make the decision about model choice? Generally, you’ll need to weigh costs and task complexity.
Model costs
As of the time of writing, Posit AI now provides access to 4 models, each with a "cost multiplier."
Posit AI is $20/mo, $15 of which directly goes to model API costs. The cost multiplier refers to how quickly conversations will consume that $15.1
Users can choose between these four models at any time, as well as control the Thinking level. The default model with Posit AI is Claude Sonnet 4.6 with Medium Thinking. Among users that have opted-in to help us improve the service, we've seen that a large majority stick with Sonnet.
Claude Sonnet or Opus will consume those $15 in credits much more quickly than Haiku or Gemma 4. Per-token, Gemma 4 will consume $15 in credits at a tenth of the rate that Claude Sonnet does, and less than a third of the rate that Haiku will. We’re currently working on features that will help users better understand which models to choose in which situations; budget-minded model choice will make those credits go further, but certain tasks require the smartest models available.
Model capability
From our perspective, a few factors should influence model choice most heavily. For one, longer conversations (often, an analogue for greater task complexity) require more intelligence. If you’ll be asking Posit Assistant to import and tidy some data, or make a simple code refactor, a smaller model will do. In contrast, implementing entire package features or autonomously integrating many data sources necessitates larger, more expensive models.
Along a similar vein, exploratory tasks like EDA may not require the most capable models. This is more related to Posit Assistant’s design than the intelligence required, per se, for specific tasks. When carrying out exploratory tasks, Posit Assistant is prompted to work more closely with the user, launching only a few tool calls and allowing the user to keep up. This is in contrast to “deliverable” tasks, like implementing a feature in a package or writing a report, where the agent will work to completion. Broadly, smaller models should be supervised more closely, and exploratory tasks loop in the user more often.
As a rule of thumb:
Looking forward
We’re very excited to offer Gemma 4 as part of Posit AI. As we wrote last week, we’re working hard to help users get as much out of those $15 in credits as possible. Offering models that are on the frontier of cost vs. intelligence is part of that push.
That said, we expect small models to continue to improve. The near future will likely bring even more capable models at a similar price point as Gemma 4. We plan to evaluate these models as they come out, with the goal of eventually offering a similarly inexpensive model that can handle an even larger share of data science tasks.
1While evaluating model providers, we were not able to find a provider to sell us Gemma by-the-token that satisfied our latency, quality, and cost expectations. We thus self-serve Gemma, paying by the GPU-hour. This allows us to provide Gemma 4 tokens faster than any provider we evaluated, at a price point on par with other model providers.

Simon Couch
Related Content

Governed AI for Public Health: Reading Free-Text Records with Snowflak...

The Missing Layer in your SCE: Why AI in Pharma Needs Skills, Not Just...
