Computer Vision with LLMs in R


kuzco is designed as a computer vision assistant library in R. Built with local LLMs in mind, kuzco utilizes Ollama to chat with LLMs through the ollamar and ellmer interfaces. The primary purpose of kuzco is to provide standardized tools for common computer vision tasks, returning results as data frames.
kuzco currently supports: classification, recognition, sentiment, text extraction and alt-text generation.
Recommended LLMs with kuzco
When selecting a local LLM, hardware limitations must be considered. These models are large and consume significant memory. With 32GB of RAM, models like gemma3 (12B), llava-phi3 (4B), or llava (7B) should all run smoothly. In the case of a library like kuzco, llava-phi3 works well and requires less memory than many other LLMs. While it may not excel at generating high-quality code or engaging dialog, in this context the primary requirement is accurate image interpretation. Neural networks are inherently well-suited for working with images, so ideally, vision-capable LLMs function much like massive pre-trained keras models. (As a side note on CPU RAM and LLM parameters: a general guideline is to keep the ratio of total memory (GB) to total model parameters (B) above one—for instance, with 32GB of RAM, the practical limit for model size is around 32B parameters.)
Computer Vision with kuzco
A common application in computer vision is image classification—determining whether an image contains a ‘cat’ or a ‘dog’, a ‘balloon’ or a ‘jellyfish’. Another example involves extracting sentiment from an image or detecting a specific object within it. Typically, torch or keras would be the go-to options for these tasks. With the advent of LLMs and their ability to handle image-to-text conversions, LLMs can serve as alternatives to traditional methods such as resnet. While a resnet-based classifier might be limited to predefined categories like ‘cat’, ‘dog’, ‘beach’, or ‘sky’, an LLM can describe the entire scene, identify the types of animals present, count the number of balloons, and perform a variety of related functions. As long as tasks are clearly defined, local models are capable of managing them effectively.
kuzco leverages the system prompts to define specific vision-based tasks for the LLMs to perform. This is an important detail, as all functions behave based on their system prompt and how well the underlying LLM can follow directions dictates the quality of the computer vision results.
In addition, kuzco supports two backends for interfacing with LLMs through Ollama: ellmer and ollamar. These backends differ in how they transmit images to Ollama. The ellmer backend includes images directly within the prompt, while ollamar utilizes Ollama’s dedicated image parameter. This variation can lead to subtle changes in how results are generated. Another key distinction involves how each backend handles structured outputs. The ellmer backend enforces strict JSON formatting from the LLM, ensuring consistency in responses, whereas ollamar merely requests JSON formatting in the system prompt but does not require it. This approach may result in more flexible, yet less predictable, output from the model.
image classification
library(kuzco)Image classification is a great starting point to demonstrate how kuzco, in combination with an LLM, can provide enhanced context about an image.
The image below features a puppy named Odin, circa 2019. While it is easy to identify the subject as a dog, there may be times when we want to extract additional context about the image or learn more about the dog itself.
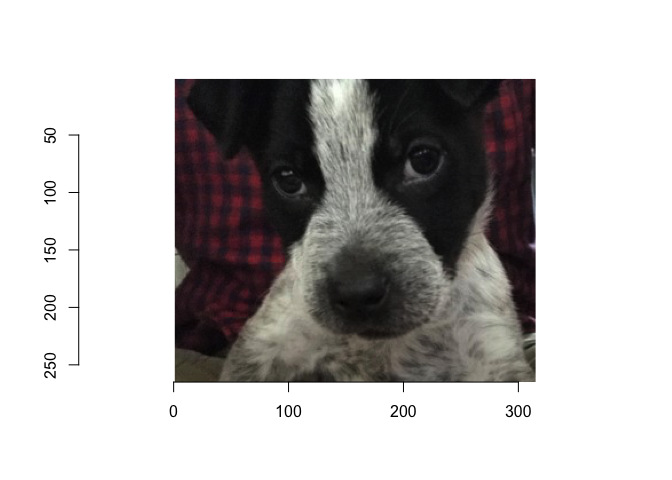
kuzco with llama3.2-vision
Below is an example of using llama3.2-vision for image classification. As the largest model featured in this blog, llama3.2-vision has a size of 7.9GB and contains 9.8 billion parameters (9.8B). Although it is relatively small compared to other widely publicized LLMs, it is a decent sized LLM for a local vision-specialized model.
tictoc::tic()
llama_classify <- llm_image_classification(
image = test_img,
llm_model = "llama3.2-vision",
backend = "ollamar"
)
tictoc::toc()39.518 sec elapsedLet’s explore what insights the LLM can provide about our image, as well as its processing time.
llama_classify |> str()'data.frame': 1 obs. of 7 variables:
$ image_classification: chr "dog"
$ primary_object : chr "dog"
$ secondary_object : chr "leash"
$ image_description : chr "A small dog with a black and white coat is sitting on a leash, looking directly at the camera."
$ image_colors : chr "#000000, #FFFFFF, #808080, #808080, #808080"
$ image_proba_names :List of 1
..$ : chr "dog, leash, collar, nose, mouth"
$ image_proba_values :List of 1
..$ : chr "0.7, 0.15, 0.1, 0.05, 0.05"llama3.2-vision performs impressively in capturing the overall context of the image and providing detailed insights, effectively enabling more thorough analysis. However, it requires a notable amount of processing time, typically between three to five times longer than a smaller vision model such as llava-phi3. This duration can vary depending on factors such as hardware specifications, the complexity of the image, and the inherent unpredictability of LLMs.
kuzco with llava-phi3
Image classification can also be performed using llava-phi3, a smaller and more efficient LLM compared to the earlier llama3.2-vision. Weighing in at approximately 2.9GB and featuring 4 billion parameters (4B), llava-phi3 is fine-tuned from Phi-3 Mini and optimized for fast, local vision-language tasks. While it is smaller in size than models often highlighted in the news, its architecture and efficiency make it well-suited for running on local hardware.
There are a lot of fine-tuned and distilled models to pull from Ollama. This is one of the interesting components of LLMs and local use cases. A larger model can distill or teach information to a smaller student model. Or generically take a base model and fine-tune it, by training it further on it’s particular use case via a larger model. However, keep in mind that as model sizes decrease, their performance may become less robust and outputs might be less consistent with kuzco’s requirements. This is why, in kuzco, the ellmer backend explicitly enforces JSON output formatting to maintain reliability; while ollamar does not, allowing more flexibility but less predictable outputs.
tictoc::tic()
llavaphi3_classify <- llm_image_classification(
image = test_img,
llm_model = "llava-phi3",
backend = "ollamar"
)
tictoc::toc()3.867 sec elapsedResults from llava-phi3:
llavaphi3_classify |> str()'data.frame': 1 obs. of 7 variables:
$ image_classification: chr "dog"
$ primary_object : chr "puppy"
$ secondary_object : chr "ears"
$ image_description : chr "A black and white puppy looking at the camera with a red plaid blanket in the background."
$ image_colors : chr "#000, #ffffff, #e63718, #f9b45c, #d9cef2"
$ image_proba_names :List of 1
..$ : chr "dog, black, white, puppy, eyes, ears, blanket"
$ image_proba_values :List of 1
..$ : chr "0.85, 0.67, 0.13, 0.8, 0.4, 0.9, 0.83, 0.6, 0.82, 0.53, 0.33, 0.55"Interestingly, llava-phi3 offers impressive performance despite its smaller size. This recent addition to the vision model ecosystem combines efficiency with strong performance capabilities, delivering classification results comparable to the larger llama3.2-vision model. Its combination of speed and accuracy makes it particularly well-suited for local deployment. Given these advantages of speed, size, and comparable accuracy, we will continue using llava-phi3 for the additional kuzco examples that follow.
image sentiment
kuzco is not limited to just image classification, it is also equipped to address a variety of image-related tasks. Image sentiment analysis is another valuable capability, allowing users to interpret the emotional tone or context of an image. In the demonstration below, note both the LLM and the backend interface to Ollama are interchangeable, showcasing kuzco’s flexibility for different workflows.
llm_sentiment <- llm_image_sentiment(
image = test_img,
llm_model = "llava-phi3",
backend = "ellmer"
)
llm_sentiment |> str()'data.frame': 2 obs. of 4 variables:
$ image_sentiment : chr "positive" "neutral"
$ image_score : num 0.83 0.45
$ sentiment_description: chr "The presence of the owner and their scent is a source of comfort for the dog." "The camera flash in the eye does not contribute to the sentiment of the image."
$ image_keywords : chr "comforting, familiar" "camera, flash, unrelated"An interesting observation to note about numbers: interpreting numbers can be challenging for LLMs, particularly for smaller models. This limitation is important to keep in mind when choosing which model to use for different image-related tasks. In this case, while the LLM effectively handled the qualitative aspect of sentiment analysis but often times smaller models do not produce a reliable numerical score.
object recognition
Object recognition provides another way to analyze images with kuzco. Instead of classifying the image at a broad level or interpreting sentiment, kuzco can detect and identify specific objects within an image. The main objective here is to screen for particular items present in the visual content. In addition to recognizing what items appear, kuzco also attempts to estimate both the number of detected objects and their general locations within the image area.
llm_object <- llm_image_recognition(
image = test_img,
llm_model = "llava-phi3",
recognize_object = "nose"
)
llm_object |> str()'data.frame': 1 obs. of 4 variables:
$ object_recognized : chr "yes"
$ object_count : int 1
$ object_description: chr "white and black nose of bulldog puppy."
$ object_location : chr "center bottom of face"This approach aligns with standard object detection techniques in computer vision, where models predict not only the class of each object but also their bounding boxes or spatial positions. By incorporating these capabilities, kuzco enables a more granular understanding of image content, making it a versatile tool for various vision-related tasks.
kuzco also supports additional image-based tasks not demonstrated above, such as text extraction and alt-text creation.
Notes on Local LLMs
Local LLMs continue to improve in task specialization, usability, and resource efficiency. Installation, configuration, and tailored prompting have all become significantly easier in recent months. As models grow smaller, faster, and more capable, tools like Ollama paired with R libraries such as ellmer and ollamar create a robust ecosystem for local deployment. Nevertheless, these technologies are still in the early stages. Challenges remain—including model hallucinations, occasional non-responsiveness, and variable compute requirements—but progress is accelerating. The prospect of running efficient, local AI assistants on edge devices is coming into focus.
Additional insights from kuzco testing: While multimodal small LLMs like Gemma3 are promising, their broader scope and lack of specialized tooling can sometimes result in lower performance. In practical use, focused vision models such as llava-phi3 tend to integrate more smoothly with kuzco and deliver more reliable results. Of course, experiences may vary, so feedback and observations from others in the community are always welcome.
Summary
Key takeaways:
For high-throughput or resource-constrained scenarios, such as processing thousands of images daily on local hardware, traditional resnets remain a strong choice.
For richer insights into a specific image, simpler code, and streamlined image processing, kuzco provides a compelling alternative.
There are hybrid workflows to consider, such as running an initial pass with torch/keras and following up with kuzco for deeper analysis or more complex classifications.
kuzco is a simple tool built on Ollama, representing only the beginning of what is possible with LLMs and local vision workflows. As a new experimental library, kuzco is open to ideas, suggestions, and feedback from the community.
A special thank you to the Posit teams, including those working on tidyverse, tidymodels, Quarto, IDEs, Shiny, Workbench, Connect, and more, for their ongoing contributions to the data science community. I am also grateful to Isabella Velásquez and Simon Couch for encouraging me to write a blog about kuzco!

Frank Hull
Related Content

Public Sector Shiny Showcase: Government Agencies Worldwide Building Data Science with R, Python, and Shiny

Snowflake Native Apps vs. Connected Apps for financial services
