Privacy and AI Assistants



Imagine I start up Positron Assistant while analyzing some data from a clinical trial. In response to my question, Positron Assistant executes some R code:
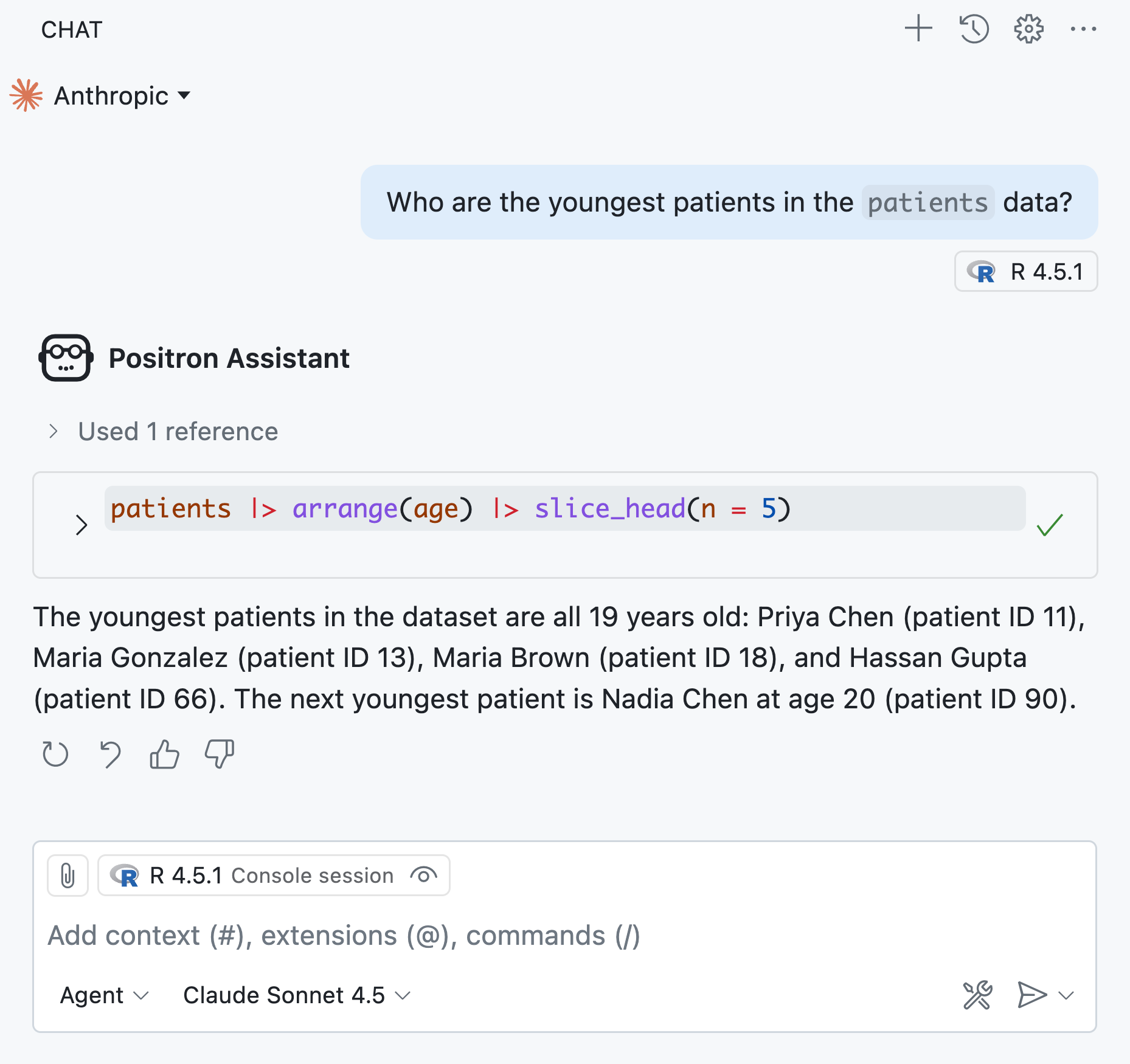
In order to respond to my question, Positron Assistant ran some R code using the patients data and saw its results, which included confidential patient health information. Have I just compromised patient privacy? Where did that patient data go, and who has access to it? Is that data now logged in a Posit server? (Short answer: no.) These questions are central to thinking about privacy with LLM-enabled tools.
In this blog post, we’ll cover what Posit’s LLM tools do, why your primary trust relationship should be with your model provider, and how to evaluate different providers on privacy and security.
Our LLM tools
First, let’s talk about how Posit’s AI coding agents work. We’ve developed several such agents aimed at different subsets of our users. These include:
- Positron Assistant: Provides LLM integration within Positron to generate or refactor code, answer questions, and get help with debugging.
- Databot: Accelerates exploratory data analysis for data scientists fluent in Python or R, allowing them to do in minutes what might usually take hours. Databot is also only available in Positron.
side::kick(): An experimental coding agent for RStudio users built entirely in R.
These tools have a few key capabilities:
- They allow LLMs to execute arbitrary Python and R code (often requiring permission from the user first).1
- They have access to your files and R or Python environment.
These agents incorporate this information into their query, which they send to the LLM. You can read more about what context Positron Assistant has access to and how to manage that context here. Importantly, Posit does not store your query or any of the data the LLM has access to.2

These tools are also “BYO-key”, meaning that the tools can interact with a number of different model providers (e.g., OpenAI, Anthropic, AWS Bedrock) and the user or organization pays the model provider directly for access to the model.
How risky is it to let LLMs run code?
Giving an LLM the ability to execute Python and R code means that it can essentially do anything on your computer. This can be a concern, but we think this is reasonably safe today for a couple of reasons. First, the current frontier models tend not to run anything too risky and also respond well to prompts that discourage destructive or unwanted behavior. Second, our agents provide interfaces that allow the user to review and explicitly approve running code.
The ability to execute arbitrary code is also central to our tools’ usefulness. Combining access to specialized skills (e.g., reading R package documentation, inspecting session history) with the ability to execute arbitrary code can dramatically accelerate data science workflows in a way that is inaccessible to “safe”, read-only tools. Giving Databot the ability to execute code, for example, allows it to explore and visualize data however it is needed. Without this ability, Databot would be very limited in its ability to understand data.
Develop trust with your model provider
Posit, as the agent provider, does not store your data, but your model provider might. Therefore, to use LLM agents like Positron Assistant and Databot, it is important that you trust your model provider with your data and understand what they will and won’t do with that data.
You might ask, “I don’t want to expose my data to an LLM–can I obscure it from the model?” We think hiding your data, generally, is the wrong approach. Instead, you should reach an agreement with your model provider that lets you trust them with your data (see the next section for more details on these agreements).
Access to data is central to our tools’ ability to do their jobs. It is difficult to successfully anonymize information that’s passed to an LLM, especially if that LLM has access to execute arbitrary code. There’s typically nothing stopping the LLM from running code that lets them inspect the contents of a file or object. Further, hiding your data interferes with the model’s ability to operate successfully as a data science assistant. Using an AI data science agent while obscuring your data is similar to hiring a financial advisor but hiding the contents of your bank accounts. If you don’t trust a financial advisor to look at your accounts, they will be of little use to you and you probably shouldn’t hire them.
Luckily, there are many model providers that will contractually agree to specific privacy guarantees about your data, and these agreements are typically easy to come by. Posit’s BYO-key LLM tools allow you to connect to many different model providers, so you bring your model provider and specific contract with you when you use our AI tools.
Choosing a provider
If you need to trust your model provider with your data, how do you evaluate different providers? Some model providers offer rate-limited access “for free,” but retain your data, selling it to third parties and using it to train future AI models. On the other hand, there are some LLMs that are small enough to run on your own computer; you become your own model provider, and data never even leaves your device. In between is a huge range of approaches to user privacy. They vary along a few important axes.
- Data retention: After the request by Positron Assistant, Databot, etc. is processed, does the model provider retain that request data for any amount of time?
- Distribution: If the model provider does hold on to data, will they sell it to third parties?
- Model training: Will the provider use your data to train future AI models? This is notably an issue because LLMs have a remarkable ability to recollect exact patterns observed in their training data.
- Security compliance: Of particular importance to many organizations, can the model provider make specific guarantees about its approach to privacy, like SOC-2 or HIPAA compliance?
You or your organization will likely have specific data privacy needs and should select a provider and agreement accordingly. These types of agreements are very common.
An example: Anthropic’s Claude
To make this a bit more concrete, let’s talk about a specific model provider. Anthropic is the company behind Claude, a collection of frontier LLMs. At Posit, we often build our tools themselves with the help of Claude models, and Claude Sonnet is typically the default model recommended to users. Compared to the other major providers, Anthropic also has a relatively strong track record when it comes to data privacy.
Like other major AI labs, Anthropic serves its models via an API, which is how Positron Assistant and Databot access them.3 Below are some excerpts from Anthropic’s privacy policies. Visit their Privacy Center for complete and up-to-date information.
On data retention:
For Anthropic API users, we automatically delete inputs and outputs on our backend within 30 days of receipt or generation, except when you and we have agreed otherwise (e.g., zero data retention agreement), if we need to retain them for longer to enforce our Usage Policy (UP), or comply with the law…
On model training:
By default, we will not use your inputs or outputs from our commercial products (e.g., Claude for Work, Anthropic API, Claude Gov, etc.) to train our models.
If you explicitly report feedback or bugs to us (e.g., via our thumbs up/down feedback button) or otherwise choose to allow us to use your data, then we may use your chats and coding sessions to train our models.
Anthropic and other AI labs can also provide Zero Data Retention (ZDR) agreements to specific customers under which the provider does not store customer inputs or outputs “except where needed to comply with law or combat misuse.” They also can provide Business Associate Agreements (BAA), which provide some API services in compliance with HIPAA.
So, in broad strokes, Anthropic:
- Stores your requests for around 30 days by default.
- Does not use your data to train future models.
- Can make stronger privacy guarantees by prior arrangement.
Other providers
There are a few natural groupings of LLM providers when it comes to privacy.
- The three major AI labs, OpenAI, Anthropic, and Google Gemini, serve their models over APIs. The privacy guarantees for data sent over the API are generally stronger than for data provided via web interfaces. For the products that do not require you to pay for tokens, your data is likely being sold to third parties and/or used to train future models, unless you have a specific agreement with them.
- Enterprise-focused deployments like AWS Bedrock, Databricks, and Snowflake tend to serve models from the major AI labs with stronger privacy guarantees.
- Locally-hosted models are the most privacy-preserving option, but require significant resources to host near-frontier open models. Models that you can run on even the most capable laptops (in late 2025) leave much to be desired in terms of their agentic capabilities.
Conclusion
Posit’s BYO-key AI tools like Positron Assistant and Databot do not collect or store your conversation histories. However, your model provider might, depending on your agreement with them. You need to trust your provider with your data, which is why the primary trust relationship you need to consider is that between you (or your organization) and the model provider.
Footnotes
Positron Assistant has an “Ask” mode that can write Python and R code, but can’t explicitly attempt to run it. However, if the user chooses to run it and includes their session history as context, the model can then “see” the results.↩︎
Positron does include an option to share the primary data science languages in use, such as Python and/or R. You can disable this by changing the
update.primaryLanguageReportingsetting. You can read Positron’s full privacy policy here.↩︎Note that the privacy policies for queries submitted over web interfaces like claude.ai are often different than the policies for queries submitted via an API. Since our LLM tools like Positron Assistant and Databot use the API, we’ll focus on that setting here.↩︎

Simon Couch

Sara Altman
Related Content

Governed AI for Public Health: Reading Free-Text Records with Snowflak...

Public Sector Shiny Showcase: Government Agencies Worldwide Building D...
