Creating ADaM Subject-Level Analysis Datasets (ADSL) with the Pharmaverse, Part 2


This blog post is based on the Clinical Reporting in R workshop from R/Pharma 2022, led by Christina Fillmore (GSK), Ellis Hughes (GSK), and Thomas Neitmann (Roche). The author thanks the instructors for sharing their valuable resources. Would you like to work through this live? Here is a ready-to-go environment on Posit Cloud!
Watch the full recording on YouTube and join R/Pharma at posit::conf(2023).
Pharmaceutical organizations must adhere to a specific set of procedures regarding their clinical trial submissions before sharing data with regulatory agencies. One crucial step in this process is the creation of subject-level analysis datasets (ADSL) and their accompanying metadata, which must comply with the Analysis Data Model (ADaM) standards.
To create ADaM datasets, a prespecified process that involves importing, tidying, and transforming data is required. Establishing a proper structure enables others to generate tables, listings, and figures more efficiently and ensures traceability. And by following this process, regulatory agencies can quickly review and approve a submission, which accelerates the release of safe and effective medicine to patients.
Creating common ADaM datasets follows a workflow that looks something like this:
- Import data that would be helpful to add to your ADaMs
- Pull in metadata
- Combine predecessor variables
- Run any calculations
- Drop unused variables
- Export the dataset
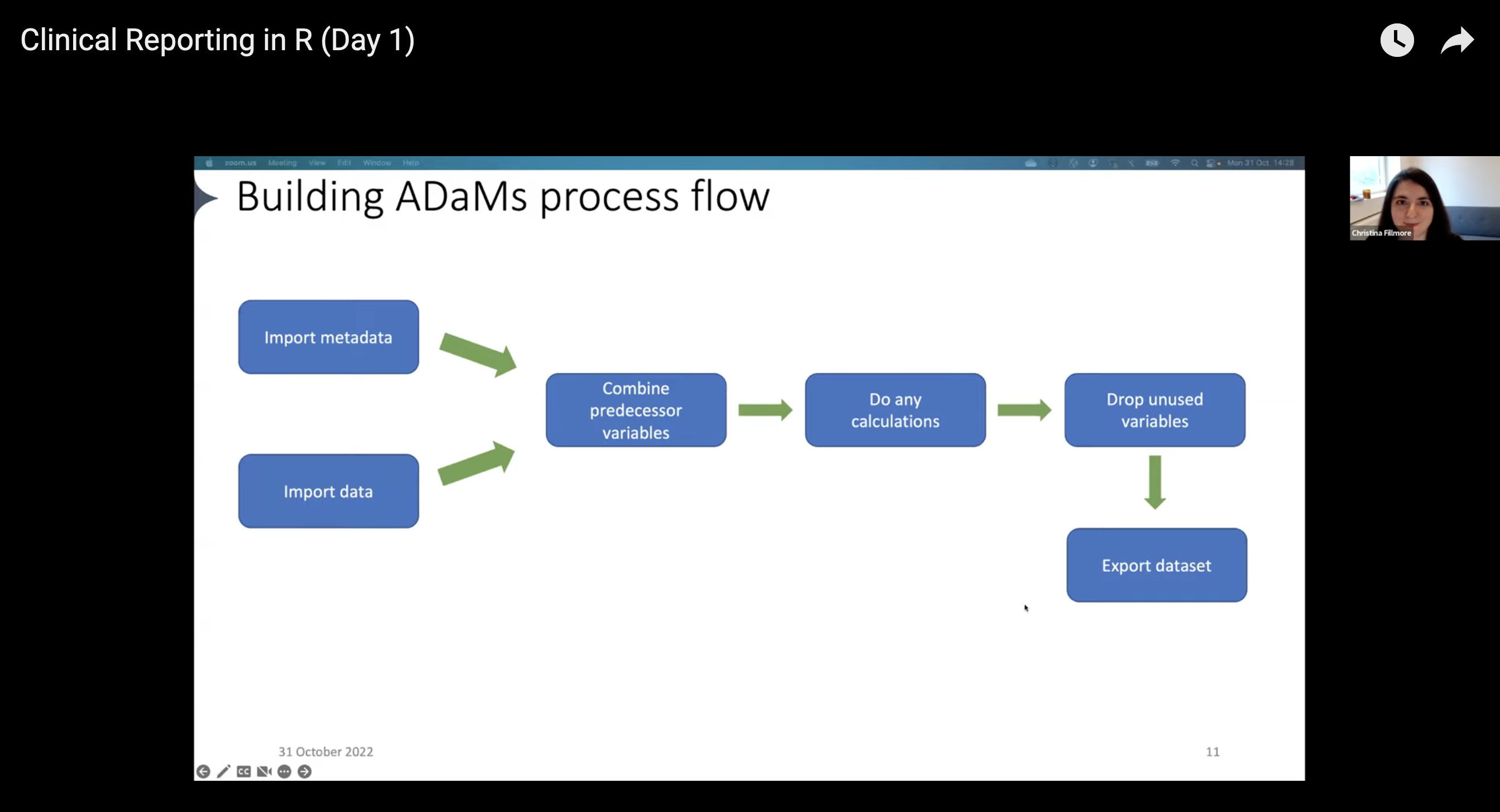
There are many different tools available that analysts can use for each step of the workflow. But often, analysts end up creating customized ways of doing things, which can be time-consuming and inefficient. Instead, it’s better to use standardized processes that can be reused across different projects. This not only saves time but also ensures consistency and accuracy in the work.
Noting this, representatives across Atorus, GSK, Janssen, and Roche started the pharmaverse, a curated stack of open-source R packages for clinical reporting. The pharmaverse is a collaboration between several pharmaceutical companies and individuals to reduce duplication efforts in clinical reporting and, ultimately, shorten the drug development process.
The pharmaverse provides analysts with a series of package to support the processes of clinical reporting, including building ADaM datasets. They don’t have to search for tools that serve their needs or create something from scratch.
With the pharmaverse, the workflow now looks like this:
- Import data: use the haven package to import
.sas7bdatfiles into R - Pull in metadata: use the metacore package to import and hold metadata, particularly for specifications
- Combine predecessor variables together: use the metatools package to enable the use of metacore objects
- Run any calculations / Drop unused variables: combine the tidyverse, metatools, and admiral for any ADaM-building needs
- Export the dataset: use xportr to export files that meet clinical standards
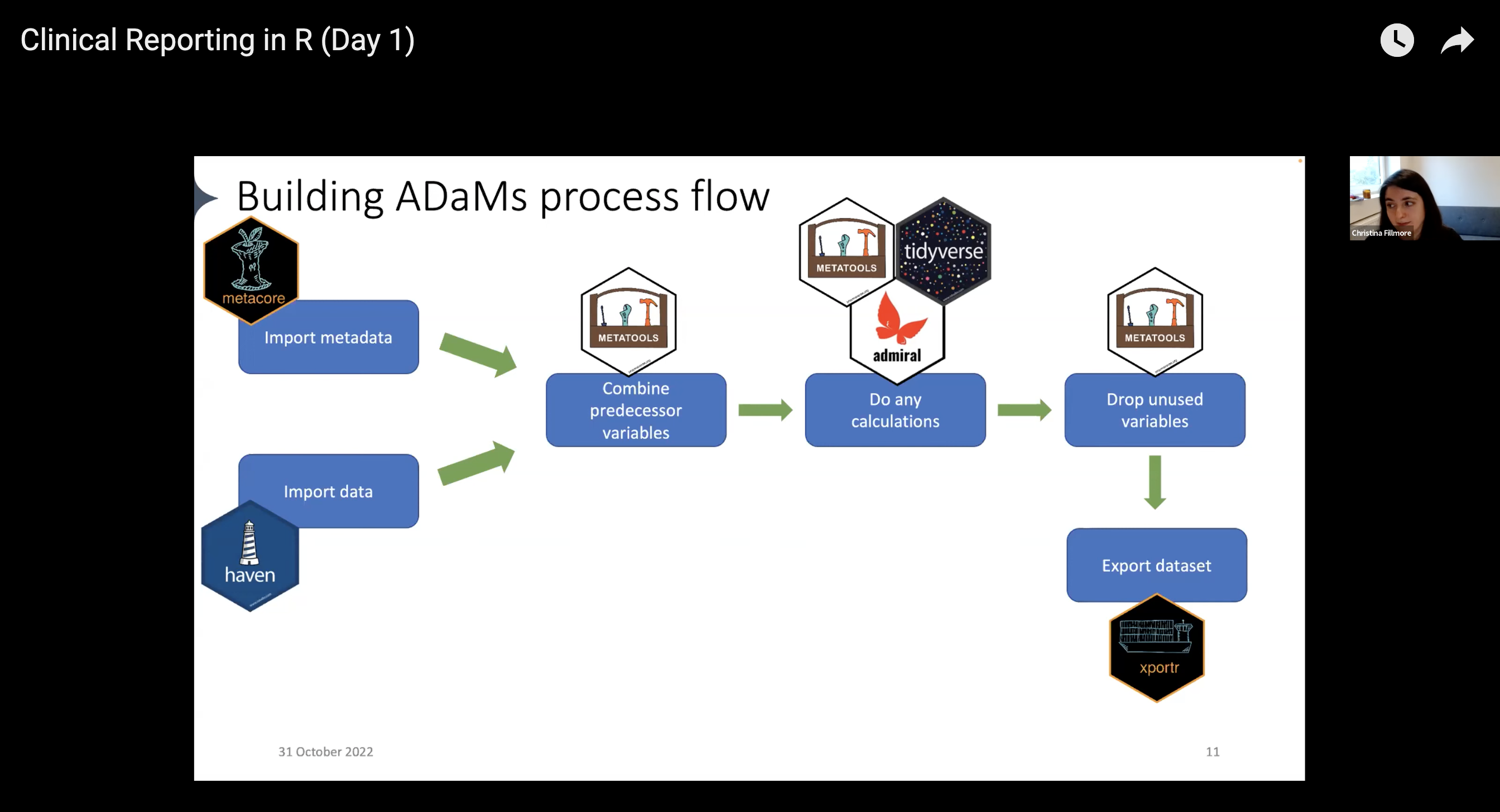
Our first blog post covered the first three steps of the workflow. This post provides a brief overview of the remaining steps. For a more in-depth understanding, we suggest referring to the two-part recording of the workshop. Let’s continue!
Picking up where we left off
In Part 1, we set up our project, loaded metadata using metacore, and used it to automate dataset creation. After creating and coding a few variables, we saw that a few required calculations.
adsl <- adsl_decode %>%
create_cat_var(adsl_spec, AGE, AGEGR1, AGEGR1N)
check_variables(adsl, adsl_spec)Error:
! In: [check_variables(adsl, adsl_spec)]
The following variables are missing: HEIGHTBL, WEIGHTBL, BMIBL, SAFFL, MITTFL,
RANDFL, TRTSDT, TRTEDT, LALVDOM, LALVSEQ, LALVVAR, LSTALVDTThis is where admiral comes in.
Derive ADaM variables and parameters with admiral
The admiral package derives variables required for creating an analysis dataset in accordance with CDISC standards. Developed by representatives from Roche and GSK, this package has been available for nearly two years and has attracted additional collaborators to expand its application to other medical fields.
The beauty of admiral is its modular approach to deriving variables. A non-admiral approach would use a single function per dataset:
pre_processing()
create_advs(
dataset_name = vs,
param_01 = ,
param_02 = ,
...,
param_99 =
)
post_processing()Instead, admiral takes one dataset, runs computations, and passes the dataset to the subsequent derivation using pipes. Instead of calling one huge function, we run small functions one by one.
vs %>%
derive_vars_a() %>%
derive_vars_b() %>%
study_vars_x() %>%
derive_params_c() %>%
project_param_y() %>%
...Below, we run through some standard derivations for ADaM datasets using the admiral package.
To continue our analysis, we import the data that we need:
dm: demographics (loaded during the metacore/metatools section)vs: vital signsex: exposuresv: study visitsae: adverse eventspre_adsl: where the metacore section above left off
library(admiral) # CRAN v0.9.1Warning: package 'admiral' was built under R version 4.4.3library(haven) # CRAN v2.5.1
library(xportr) # CRAN v0.1.0Warning: package 'xportr' was built under R version 4.4.3vs <- file_load(vs_url, "vs", "xpt")
vs <- read_xpt("vs.xpt")
ex <- file_load(ex_url, "ex", "xpt")
ex <- read_xpt("ex.xpt")
sv <- file_load(sv_url, "sv", "xpt")
sv <- read_xpt("sv.xpt")
ae <- file_load(ae_url, "ae", "xpt")
ae <- read_xpt("ae.xpt")
pre_adsl <- adslWe begin by creating columns for the baseline characteristics for height and weight. The admiral function derive_vars_transposed() transposes our desired data onto our ADSL. We pick the data to merge onto (vs) and define the required parameters. Check out ??derive_vars_transposed to see the help file.
adsl_bl <- pre_adsl %>%
derive_vars_transposed(
select(vs, USUBJID, VSTESTCD, VSSTRESN, VSBLFL), # Dataset to transpose and merge onto
by_vars = exprs(USUBJID), # Merge keys
key = VSTESTCD, # Names of transposed variables
value = VSSTRESN, # Values of transposed variables
filter = VSTESTCD %in% c("HEIGHT", "WEIGHT") & VSBLFL == "Y" # Restrict records to just height and weight
) %>%
# Do some cleanup
rename(HEIGHTBL = HEIGHT, WEIGHTBL = WEIGHT) %>%
mutate(BMIBL = compute_bmi(HEIGHTBL, WEIGHTBL))Now, we want to know when the treatments start and end for our patients in ADSL. This information is available in the ex file. In particular, we want to know the first and last date someone took a dose greater than 0 or received a placebo.
Taking a quick look at our imported dataset, we see that the date variables are not dates but character values:
typeof(ex$EXSTDTC)[1] "character"This mismatch presents an issue for our analysis. We need to convert the character vectors representing dates into date types first. We create a new object called ex_dt that pipes the ex dataset into the derive_vars_dt() function. This function derives a date from a date-character vector, so the values are the proper type.
ex_dt <- ex %>%
derive_vars_dt(
new_vars_prefix = "EXST",
dtc = EXSTDTC
) %>%
derive_vars_dt(
new_vars_prefix = "EXEN",
dtc = EXENDTC
)Checking the type of our date variables in this new dataset, we see they are now date types.
lubridate::is.Date(ex_dt$EXSTDT)[1] TRUEWe can derive our treatment start/end dates. The derive_vars_merged() function adds new variables to the input dataset based on variables from another dataset. Within the function, we can specify what we are looking for: that we want the first dose (mode = "first"), that we want only valid records (filter_add = EXDOSE > 0 | (EXDOSE == 0 & str_detect(EXTRT, "Placebo"))), we want to order doses by specific columns (order = exprs(EXSTDT, EXSEQ)), etc. The admiral package has many ways to fine-tune variables’ derivation.
We also want the last treatment date, so we pipe in another derive_vars_merged() block specifying that the mode is last.
adsl_ex <- adsl_bl %>%
derive_vars_merged(
dataset_add = ex_dt,
by_vars = exprs(STUDYID, USUBJID), # Merge to single record
order = exprs(EXSTDT, EXSEQ),
new_vars = exprs(TRTSDT = EXSTDT),
mode = "first",
filter_add = EXDOSE > 0 | (EXDOSE == 0 & str_detect(EXTRT, "Placebo"))
) %>%
derive_vars_merged(
dataset_add = ex_dt,
by_vars = exprs(STUDYID, USUBJID),
order = exprs(EXENDT, EXSEQ),
new_vars = exprs(TRTEDT = EXENDT),
mode = "last",
filter_add = EXDOSE > 0 | (EXDOSE == 0 & str_detect(EXTRT, "Placebo"))
)Another common task is adding safety flags, which we can do with admiral. We will add a safety population flag, a modified intent to treat flag, and a randomization flag.
The derive_var_merged_exist_flag() helps us do this: flag a condition as TRUE if it is met (a patient received a valid dose) and FALSE if it is not (a patient did not receive a valid dose).
Like before, we can pipe our modified dataset and run derive_var_merged_exist_flag() for each flag we’d like to add.
adsl_saff <- adsl_ex %>%
derive_var_merged_exist_flag(
dataset_add = ex,
by_vars = exprs(STUDYID, USUBJID),
new_var = SAFFL,
condition = (EXDOSE > 0 | (EXDOSE == 0 & str_detect(EXTRT, "Placebo")))
) %>%
derive_var_merged_exist_flag(
dataset_add = sv,
by_vars = exprs(STUDYID, USUBJID),
new_var = MITTFL,
condition = (VISITDY >= 56)
) %>%
mutate(RANDFL = if_else(ACTARMCD %in% c("P", "A"), "Y", NA_character_))Finally, let’s derive a variable for the last date known alive. We want to consider adverse events (ae), exposure (ex), and treatment date as our sources.
How do you look across all these to get an accurate last date known alive? The derive_var_extreme_dt() derives the first or last date from multiple sources, so we don’t have to search across datasets ourselves.
First, we create a ‘framework’ for the datasets we want to use using date_source(). This function allows us to specify the variables to consider and creates a special object to feed into derive_var_extreme_dt().
The traceability_vars parameter adds context to the derivations. It defines the domain, sequence identifier, and variable from which the last date alive came.
# From treatment start date
ex_start_src <- date_source(
dataset_name = "ex",
date = EXSTDT,
set_values_to = exprs(
LALVDOM = "EX",
LALVSEQ = EXSEQ,
LALVVAR = "EXSTDTC"
)
)Warning: `date_source()` was deprecated in admiral 1.2.0.
ℹ Please use `event()` instead.
✖ This message will turn into an error at the beginning of 2027.
ℹ See admiral's deprecation guidance:
https://pharmaverse.github.io/admiraldev/dev/articles/programming_strategy.html#deprecation# From treatment end date
ex_end_src <- date_source(
dataset_name = "ex",
date = EXENDT,
set_values_to = exprs(
LALVDOM = "EX",
LALVSEQ = EXSEQ,
LALVVAR = "EXENDTC"
)
)We also want to consider adverse effects, so we also use date_source() on the ae dataset.
ae_dt <- ae %>%
derive_vars_dt("AEST", AESTDTC) %>%
derive_vars_dt("AEEN", AEENDTC)
ae_start_src <- date_source(
dataset_name = "ae",
date = AESTDT,
set_values_to = exprs(
LALVDOM = "AE",
LALVSEQ = AESEQ,
LALVVAR = "AESTDTC"
)
)
ae_end_src <- date_source(
dataset_name = "ae",
date = AEENDT,
set_values_to = exprs(
LALVDOM = "AE",
LALVSEQ = AESEQ,
LALVVAR = "AENTDTC"
)
)Finally, we use ADSL as our last source.
adsl_dt_src <- date_source(
dataset_name = "adsl",
date = TRTEDT,
set_values_to = exprs(
LALVDOM = "ADSL",
LALVSEQ = NA,
LALVVAR = "TRTEDT"
)
)Now, we can use the derive_var_extreme_dt() function to look across all of our sources.
adsl_lstalv <- adsl_saff %>%
derive_var_extreme_dt(
new_var = LSTALVDT,
ae_start_src, ae_end_src, ex_start_src, ex_end_src, adsl_dt_src,
source_datasets = list(ae = ae_dt, ex = ex_dt, adsl = adsl_saff),
mode = "last"
)Warning: `derive_var_extreme_dt()` was deprecated in admiral 1.2.0.
ℹ Please use `derive_vars_extreme_event()` instead.
✖ This message will turn into an error at the beginning of 2027.
ℹ See admiral's deprecation guidance:
https://pharmaverse.github.io/admiraldev/dev/articles/programming_strategy.html#deprecationWarning: `derive_var_extreme_dtm()` was deprecated in admiral 1.2.0.
ℹ Please use `derive_vars_extreme_event()` instead.
✖ This message will turn into an error at the beginning of 2027.
ℹ See admiral's deprecation guidance:
https://pharmaverse.github.io/admiraldev/dev/articles/programming_strategy.html#deprecation
ℹ The deprecated feature was likely used in the admiral package.
Please report the issue at <https://github.com/pharmaverse/admiral/issues>.To finish up, we go back to metatools. With the metatools functions, we can order and select our columns based on our spec document, set variable labels, and check our data against the control terminology.
adsl <- adsl_lstalv %>%
order_cols(adsl_spec) %>%
set_variable_labels(adsl_spec) %>%
check_ct_data(adsl_spec) %>%
check_variables(adsl_spec)No missing or extra variablesWe can continue using the admiral functions to derive whatever variables we need to finish up our ADaM dataset. The modular approach makes it easy to add on. The parameters in the functions help specify what we need.
Export XPT files with xportr
The final step in the workflow is exporting the dataset to an XPT format. The xportr functions associate the essential metadata in our R data frame, allowing us to transport them to clinical data set validator applications or regulatory agencies.
adsl %>%
xportr_label(adsl_spec, domain = "ADSL") %>%
xportr_df_label(adsl_spec, domain = "ADSL") %>%
xportr_write("adsl.xpt")And that’s it! With the pharmaverse packages, we have completed our workflow and created an ADaM dataset.
Learn more
We hope you enjoyed the second post on how to use the pharmaverse for creating ADaM ADSL with the pharmaverse. We showed only some of the available packages and functions; check out the breadth of the pharmaverse on the website and peruse the provided examples.
Again, we thank the instructors of Clinical Reporting in R for their materials. Please watch the Day 1 and Day 2 recordings for more detailed information and for walkthroughs on other parts of the clinical reporting workflow.
Join the pharma community driving innovation with open source
If you want to join the vanguard in the pharmaceutical field, register for posit::conf(2023)! We are excited to partner with R/Pharma to host their in-person program at our upcoming annual user conference. Leaders from various pharmaceutical companies such as Roche and Novartis will oversee the discussions focused on the “next-generation” open-source tooling for drug development.
We are hosting two activities specific to the pharmaceutical industry:
- The “R/Pharma Roundtable Summit” for program leaders and people leading Open Source initiatives, and
- “Leveraging And Contributing To The Pharmaverse For Clinical Trial Reporting In R” workshop for data professionals.
Read the R/Pharma at posit::conf(2023) blog post and register today: http://pos.it/pharmasummit.

Isabella Velásquez
Related Content

Score a Disease Surveillance Model Inside Snowflake, Without Moving

Governed AI for Public Health: Reading Free-Text Records with Snowflak...
